Build a real-time knowledge store for generative AI.
Store vectors, full-text, and structured data in one database. Retrieve with hybrid search and fusion re-ranking. Serve fresh, multi-modal context to LLMs and agents in milliseconds.
The knowledge store that keeps your AI accurate, fast, and current.
Real-time fresh context
CDC, Kafka streaming, and HTTP ingest at 10M rows/s. New data searchable in ~1 second. No more stale embeddings causing confident wrong answers.
94% retrieval relevance
Hybrid Search fuses vector similarity, BM25 keyword matching, and SQL filters with Reciprocal Rank Fusion. 94% relevance vs 58% with pure vector search.
One store for every data type
Vectors, full-text, structured tables, and semi-structured JSON in one database. Replace Pinecone + Elasticsearch + PostgreSQL with one query path.
Where teams deploy VeloDB knowledge stores.
Ground LLM answers in fresh, internal documents
Policy docs, support tickets, product specs — chunked, embedded, and searchable via hybrid search. The LLM retrieves current context, not a 6-month-old PDF snapshot.
Manage billions of multimodal training samples
AISpeech manages 10B+ samples across 500TB with millisecond version switching, 80% storage reduction, and full data lineage for model reproducibility.
Search text, vectors, labels, and metadata in one query
Horizon Robotics queries nearly 1 trillion records across four search modes — text, vector embeddings, bitmap labels, and JSON metadata — on a single engine.
Serve real-time context to AI agents via MCP
Agents query VeloDB directly through the MCP Server protocol. Hybrid search returns structured + semantic context in sub-100ms for agent reasoning loops.
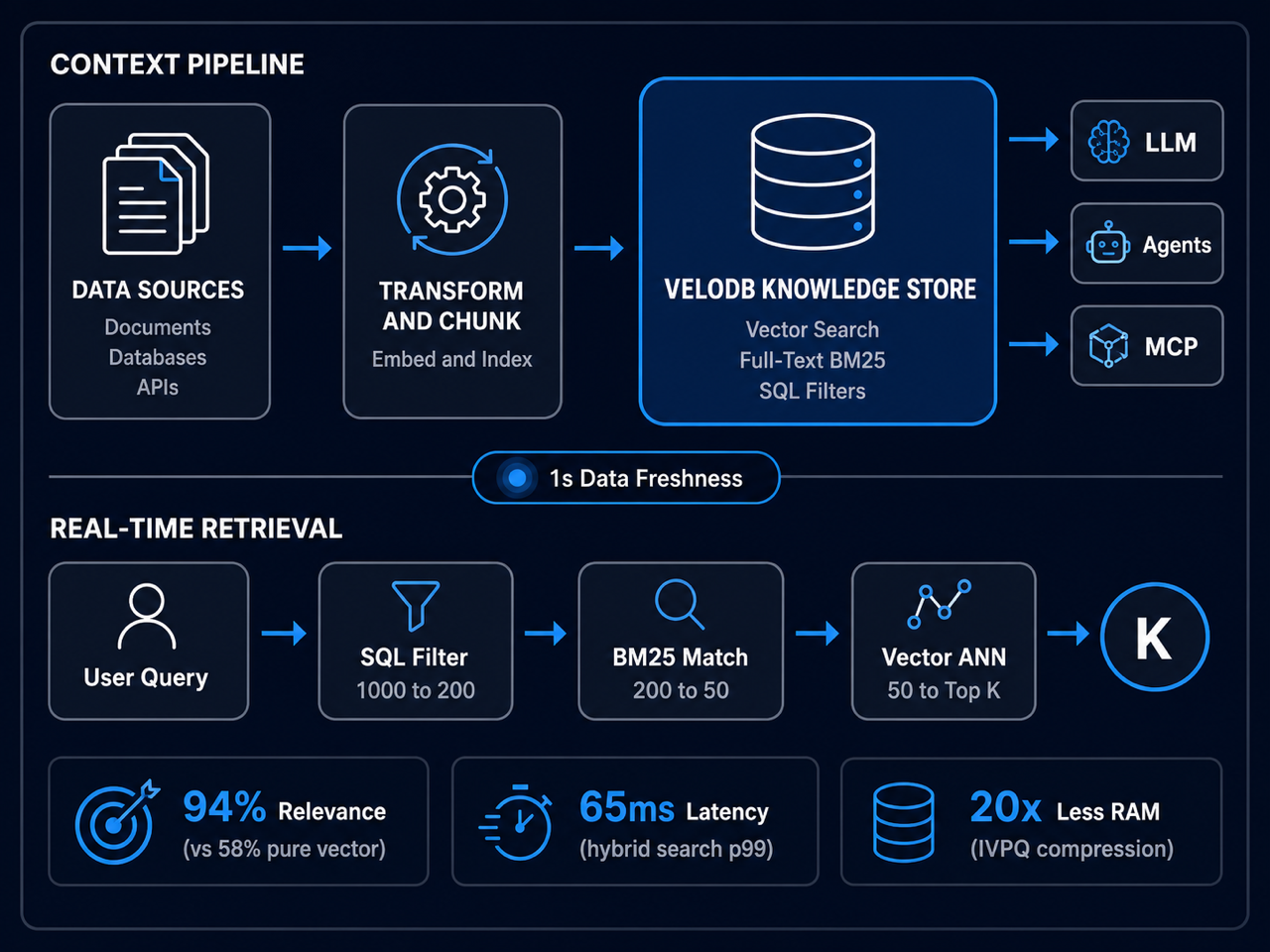
The real-time AI context stack.
Raw data enters through CDC, streaming, or HTTP push. An embedding pipeline like CocoIndex transforms, chunks, and embeds your documents with incremental processing -- only changed documents are reprocessed. VeloDB stores everything in one engine and serves AI applications through hybrid search via MCP Server, MySQL protocol, or REST API.
Progressive filtering. Hybrid search. Fusion re-ranking.
VeloDB doesn't run three searches in parallel and hope for the best. It progressively narrows the candidate set at each stage -- structured filtering first, keyword matching second, vector search third. Expensive operations run on a tiny, pre-filtered subset.

Structured Pre-Filtering (~50ms)
B-tree indexes, zone maps, and partition pruning apply hard constraints -- location, date, category, access permissions. The candidate set drops from millions to thousands before any search operation begins.
BM25 Full-Text (~200ms)
Inverted indexes with global BM25 scoring find exact keyword matches. Unlike per-segment scoring (which caused ranking instability at ByteDance), VeloDB calculates statistics across the entire table. Supports English, Chinese, and multilingual tokenizers.
Vector Similarity + Fusion (~150ms)
HNSW indexes run semantic search on the pre-filtered subset. IVPQ compresses 768-dim vectors from 3KB to 8 bytes (384x ratio). Reciprocal Rank Fusion combines rankings from all three stages: documents that score well across multiple signals rank highest.
Production results. Not benchmarks.
ByteDance needed to search 1 billion+ vectors for talent matching. Pure vector search delivered only 58% relevance -- a recruiter searching for Python developers in San Francisco got candidates from Seattle. Rankings shuffled every time database segments merged because BM25 was calculated per-segment, not globally.
Apache Doris 4.0 with progressive filtering changed everything: structured constraints first (50ms), keyword matching second (200ms), vector search third (100ms), fusion ranking last (50ms). IVPQ compression reduced 768-dimension vectors from 3,072 bytes to 8 bytes -- a 384x compression ratio. Relevance jumped from 58% to 94%. Latency dropped from 2.8 seconds to 400 milliseconds. Memory shrank from 10TB across 20-30 servers to 500GB on one server.
AISpeech / 思必驰
Conversational AI company managing 10 billion+ multimodal training samples across 500TB. Before: training data scattered across different storage systems, maintained manually by different teams. Conflicting data versions undermined model consistency. Algorithm engineers wasted time searching for and re-annotating data. After building on Apache Doris: columnar storage compressed annotation data 80%. Version-based partitioning enables millisecond dataset switching -- active versions on SSD, history auto-migrates to HDD. Point query QPS hit 30,000 with row-store optimization (CPU: 80% --> 10%). Now planning upgrade to Doris 4.0 for vector search to fully replace Elasticsearch.
Horizon Robotics
Autonomous driving company processing petabytes daily. Replaced three separate systems -- Hive/Iceberg for analytics, Zilliz for vectors, Elasticsearch for search -- with one Doris engine. Four search modes unified: text, vector, label bitmap operations, and JSON metadata. Engineers stopped hopping between systems. Query times dropped from minutes to seconds on approximately 1 trillion records.
Go deeper.
ByteDance: How Billion-Scale Vector Search Was Solved with Apache Doris 4.0
Read more -->CocoIndex + VeloDB: The Real-Time AI Context Stack
Read more -->Apache Doris 4.0: Native Hybrid Search for AI Workloads
Read more -->VeloDB for AI: The AI-Ready Analytics Database
Read more -->Apache Doris 4.1: Unified Storage and Retrieval for AI and Search
Read more -->How to Build an AI Knowledge Store with VeloDB
Read more -->Start building your knowledge store.
How to Chunk and Embed
Step-by-step guide to preparing your data for VeloDB's hybrid search. Chunking strategies, embedding models, and indexing best practices.
Read the guide -->Working with Vectors in VeloDB
Create HNSW indexes, run vector similarity queries, configure IVPQ compression, and build hybrid search with RRF.
Read the guide -->Try VeloDB Cloud
14-day free trial for SaaS. 30 days of free compute for BYOC. No credit card required.
Start Free Trial -->Bring your retrieval workload.
We will map the path.
A 30-minute architecture review with a VeloDB solutions engineer. Bring your schema, your query patterns, and your freshness requirements. We will show you where a unified knowledge store eliminates complexity.