Build a real-time data warehouse on an open lakehouse.
Sub-second analytics on petabyte-scale data. Real-time ingestion in 1-5 seconds. Native Iceberg, Hudi, and Delta Lake support. One unified engine that replaces 6+ components -- without prohibitive cost.

The data warehouse that makes analytics real-time, unified, and affordable.
Sub-second analytics at any scale
Vectorized execution, MPP architecture, and CBO optimizer deliver 22x faster TPC-H performance than Presto. Complex multi-table JOINs return in milliseconds.
Real-time ingestion in 1-5 seconds
StreamLoad, Flink CDC connector, and RoutineLoad ingest millions of records per second with 1-5 second end-to-end latency. No more T+1 waiting.
Open data lakehouse, no lock-in
Full Iceberg V3 read support, Hudi and Delta Lake integration via Catalog. Query your data lake directly without moving data.
One engine replaces six tools
Replace MongoDB, Elasticsearch, Kylin, Druid, Trino, and Hive with one system. Simplify your stack, reduce operational cost.
Where teams deploy VeloDB data warehouses.
Ad analytics & attribution
Kwai (400M DAU) consolidated ClickHouse + Elasticsearch into one VeloDB warehouse. 4,000+ query templates across 700 fields power real-time campaign attribution and revenue reporting.
Financial & transaction reporting
Planet processes 3B payment events daily. Migrated from Snowflake, cutting cost from $25K to $5K/month. Multi-table JOINs return in 1.5 seconds.
User behavior analysis
JD.com ingests 10B rows daily for search analytics. 60M rows/min ingestion, 10K QPS, 150ms latency power live A/B testing and conversion funnel dashboards.
Enterprise BI & KPI monitoring
Async materialized views replace external ETL schedulers. BI tools query via MySQL protocol at 30K+ QPS. KPIs refresh in seconds, not next morning.
Engineered for speed, freshness, and simplicity.
Every layer of VeloDB is optimized for real-time analytical workloads -- from how data is written and stored to how queries are planned and executed.
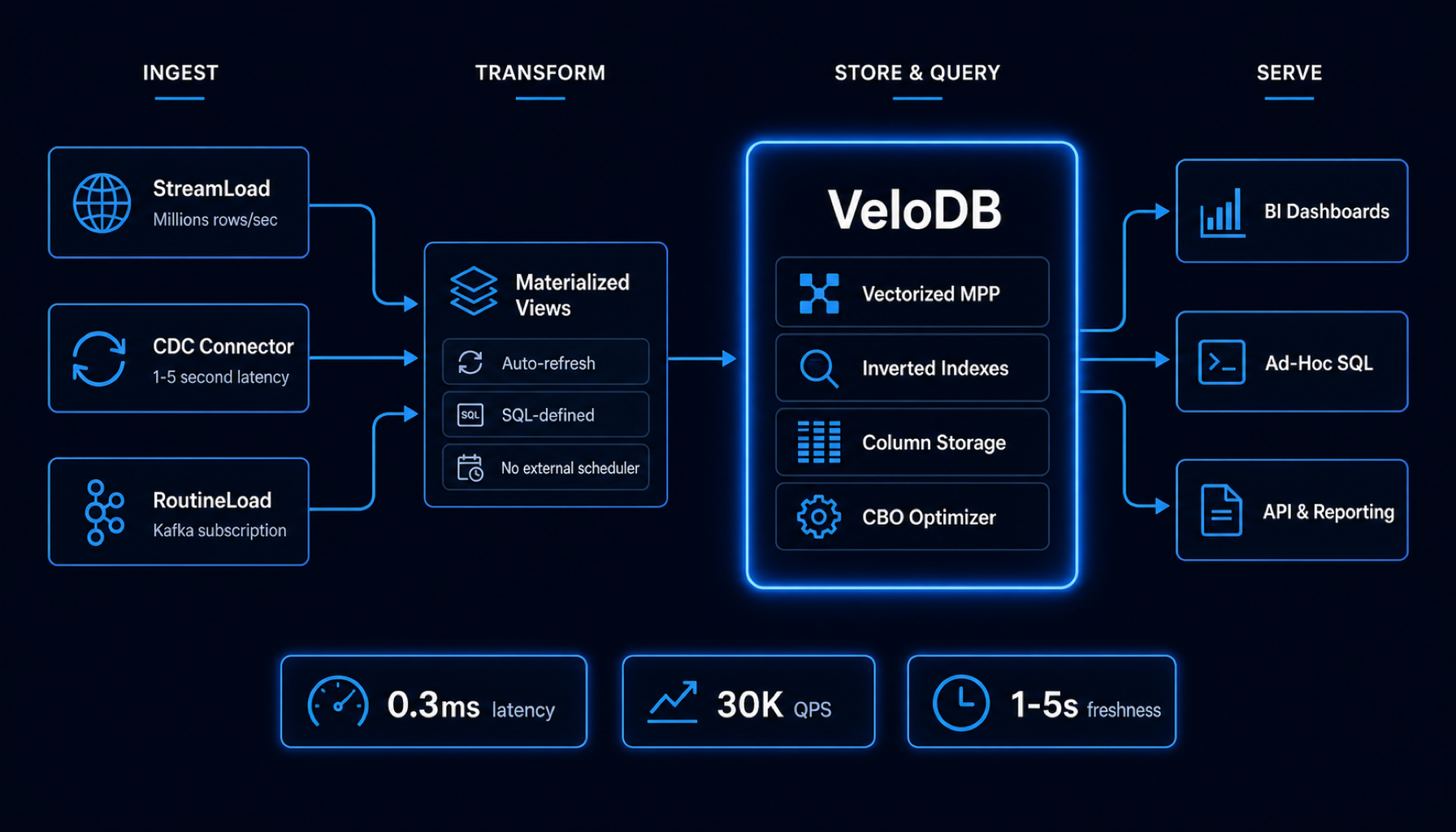
Async Materialized Views
SQL-defined transformations that auto-refresh as new data arrives. Build your entire ODS-to-ADS pipeline inside VeloDB -- no external scheduler, no Airflow, no DAG management. Multi-table views support complex JOINs and transparently accelerate queries.
MVCC High-Concurrency Writes
Append-based writing with Multiversion Concurrency Control handles thousands of concurrent writes. UniqueKey tables with Merge-on-Write deliver real-time upserts at 10-second freshness with 5-10x better query performance than Merge-on-Read.
Vectorized + MPP + CBO Engine
Vectorized processing with SIMD on both x86 and ARM. MPP architecture distributes computation across nodes. CBO optimizer with cost-based join reordering, predicate pushdown, and Runtime Filters prunes data before it touches memory.
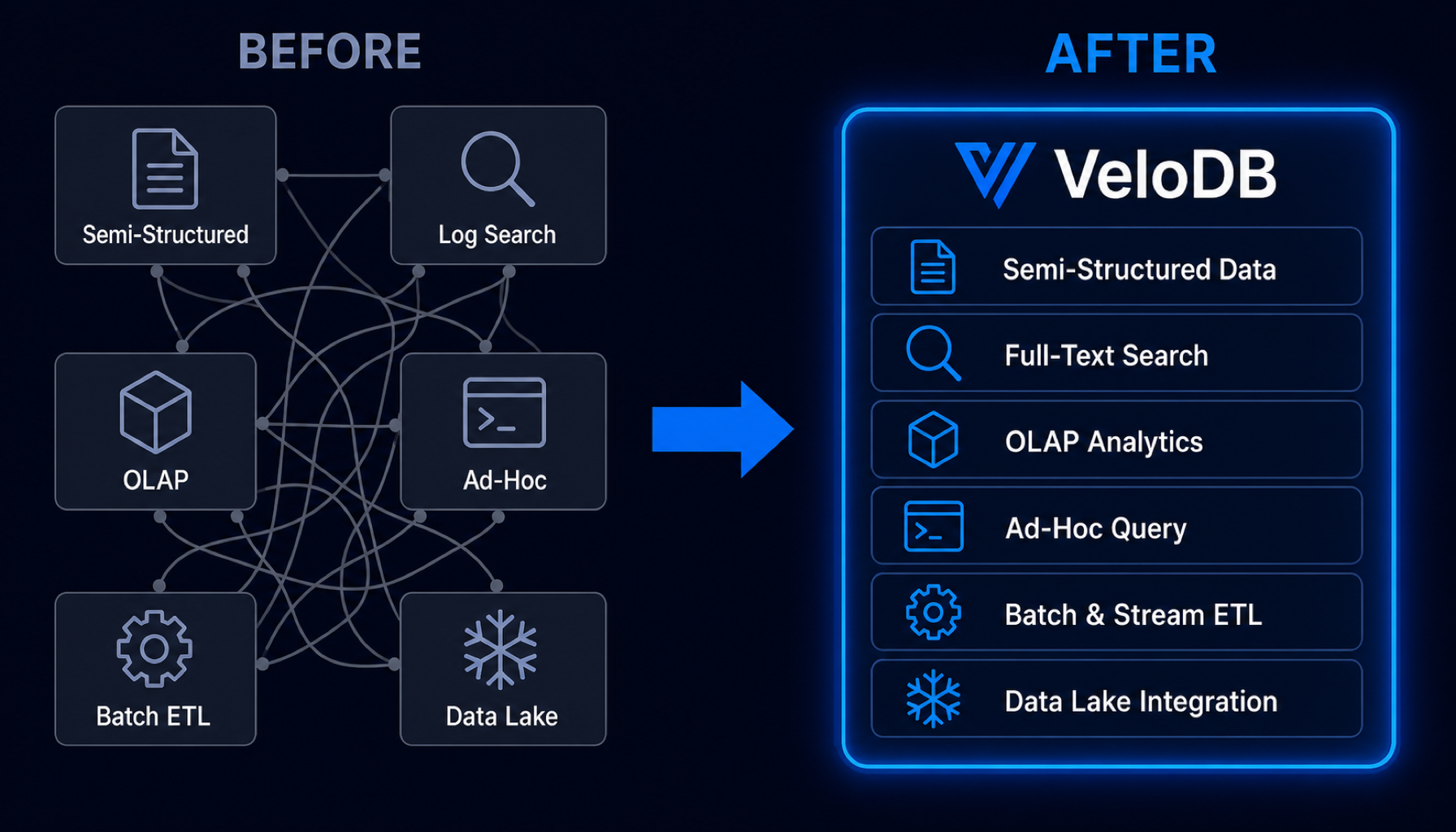
One engine replaces six.
Traditional architectures spread workloads across MongoDB for semi-structured data, Elasticsearch for search, Kylin or Druid for OLAP, Trino for ad-hoc queries, Hive/Spark for batch processing, and separate data lake formats. Each system requires its own team, its own tuning, its own failure modes.
VeloDB handles all six workloads in a single system. Simplify your technology stack, reduce data migration between systems, and lower total cost of ownership.
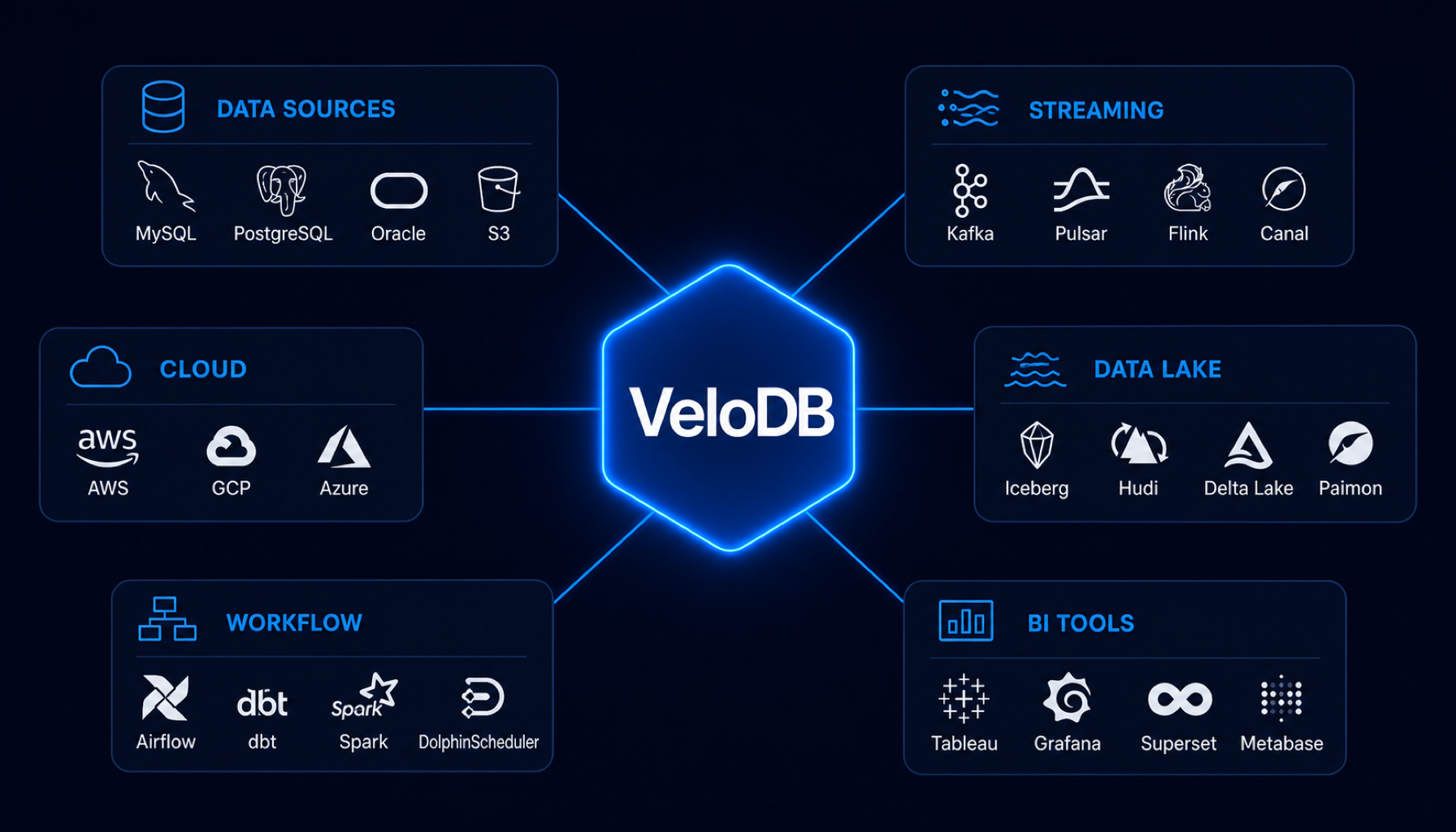
Rich ecosystem integration.
VeloDB integrates with every layer of your data stack. No rip-and-replace required -- plug into your existing infrastructure and start querying.
Production results. Not benchmarks.
Ave.ai serves 10 million users and 500K daily active users with real-time analytics across 190+ blockchains and 500+ DEXs. Their PostgreSQL backend couldn't handle the mixed workload of real-time transaction tagging -- sniper detection, front-running analysis, whale tracking, smart money signals -- alongside complex analytical queries on a 10TB+ blockchain transaction database.
After evaluating HBase, Snowflake, ClickHouse, Hologres, GaussDB, and TiDB, Ave.ai chose VeloDB. Inverted indexes on 10 high-frequency columns with 64-bucket hash distribution handle ~5,000 sustained writes/second. End-to-end latency dropped below 5 seconds. Operating costs fell by more than 50%. Decimal256 support handles 60+ digit precision for on-chain financial calculations.
Kwai -- Trillion-Scale Ad Analytics
Kwai (400M DAU) replaced ClickHouse + Elasticsearch with VeloDB for unified ad analytics. Slow query rate dropped from 35% to under 5%. Point query latency fell from 250ms to 12ms (20x). Infrastructure shrank from 800 instances to 17, handling trillions of rows across 700 core fields and 4,000+ query templates.
Planet -- From Snowflake, 80% Cost Savings
Planet migrated from Snowflake to VeloDB, cutting monthly cost from $25,000 to $5,000. A 20M-row OLAP query went from 5s to 0.9s (4.6x). Multi-table JOINs dropped from 8s to 1.5s. Micro-batch loading latency improved from 5-10 minutes to 1-2 seconds -- 300x faster ingestion for 3 billion events per day.
Powering analytics at scale.
Deep dives and customer stories.
Why Ave.ai Chose VeloDB Over ClickHouse & Snowflake for Web3 Analytics
Read more →How Kwai Unified Trillion-Scale Ad Analytics: From 800 to 17 Instances
Read more →From Snowflake to Apache Doris: 80% Cost Savings with Real-Time Analytics
Read more →Ultimate OLAP Showdown: Apache Doris vs ClickHouse vs Snowflake
Read more →Set Up a Lakehouse with PostgreSQL, Apache Iceberg, and Apache Doris
Read more →How Advance.AI Cut Log System Costs by 50% with Apache Doris
Read more →Get started in minutes.
Quick Start Guide
Deploy a VeloDB cluster, create your first table, and run your first analytical query. From zero to sub-second results in under 15 minutes.
Follow the guide →Free Trial on VeloDB Cloud
Spin up a fully-managed cluster on AWS, GCP, or Azure. No credit card required. Includes StreamLoad ingestion, materialized views, and full SQL access.
Start free trial →Migration Guide
Step-by-step instructions for migrating from ClickHouse, Presto/Trino, Hive, or Greenplum. MySQL-compatible SQL means minimal query rewrites.
Read migration docs →Bring your data. We'll make it real-time.
Stop waiting for T+1 batch reports. Stop managing six different analytics tools. Build a real-time data warehouse on an open lakehouse with sub-second query performance.